

Most sites do not lose search traffic because something breaks overnight. They lose it because the site grows, content spreads out, links shift, and Google slowly stops treating large parts of the site as important.
That slow drift is what I call indexing debt.
Indexing debt is the gap between what your site has (all URLs that exist), and what search engines actively crawl, index, and keep fresh (the URLs that actually have a chance to rank and convert)

It builds quietly. Then one day, traffic is down, leads are softer, conversions dip, and the team starts chasing “what changed” when the truth is: the site has been accumulating indexing debt for months or years.
How old pages quietly lose visibility
A page does not need to be “bad” to lose visibility.
It just needs to become less connected, less updated, and less obviously important.
Google has finite crawling resources and prioritizes what it thinks is worth revisiting, especially on bigger or frequently updated sites. Google’s own crawl budget documentation makes it clear this is a real constraint for large sites and that not every URL will be crawled at the same pace.

So what happens in the real world?
A page is published, it gets crawled, it gets indexed, maybe it ranks. Then:
- internal links get removed during redesigns
- categories change
- navigation shifts
- newer pages steal internal link attention
- the page stops receiving updates
Over time, that page becomes a weaker “candidate” for crawl priority. It might still be indexed, but it is not being revisited often. It goes stale in Google’s understanding of your site, and rankings can fade without any dramatic event.
This is why indexing debt is so sneaky. Nothing looks broken, but performance gradually erodes.
There is a brutal stat that helps frame the scale of the problem: Ahrefs has reported that 90.63% of pages get zero organic traffic from Google. There are many reasons this happens, but “not indexed or not kept visible” is part of the story.
That is a huge pool of content that exists, but does not participate in search.
Orphaned URLs and forgotten updates
Indexing debt accelerates when URLs become orphaned.
Orphan pages are pages with no internal links pointing to them, meaning they sit outside your site structure. Many SEO platforms and teams treat orphan pages as “invisible” because they are hard for search engines (and users) to discover through normal navigation.
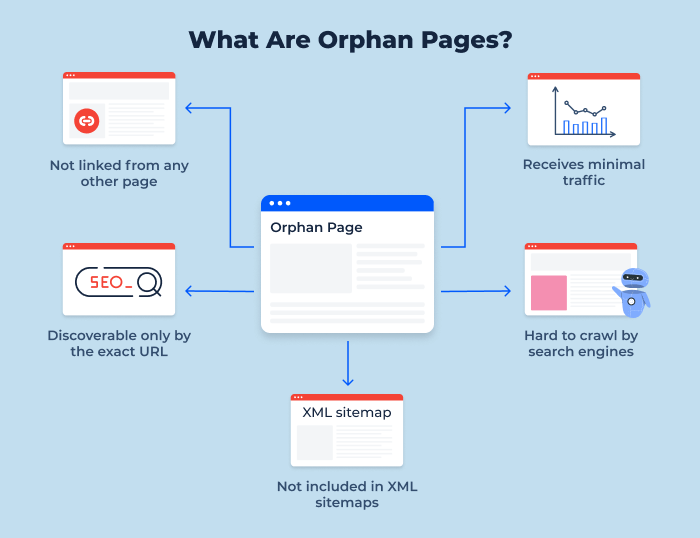
Google itself emphasizes that links help it find pages and understand relevance. Internal linking is not just UX, it is discovery and prioritization.
Orphaning happens in normal growth:
- old campaign landing pages that still exist but are no longer linked
- legacy product pages replaced by new versions, with no redirect
- blog posts that used to be in a category hub, but the hub was removed
- CMS migrations that preserve URLs but lose internal link structure
- programmatic pages generated and later forgotten
Then there is the second, more painful version of indexing debt: updated pages that do not get reprocessed fast enough.
You update your pricing page, you refresh a feature page, you improve an article, and you assume Google will notice quickly.
Sometimes it does. Sometimes it does not.
Even the tools you rely on can lag. In late 2025, Search Engine Journal reported Google confirmed delays in Search Console’s Page indexing report, meaning teams may see stale indexing data in the report even when real crawling and indexing continues normally.
That detail matters because it highlights a common operational trap:
- teams already do not check indexing often
- when they do check, the reporting may lag
- so indexing debt keeps building, unnoticed
Why re-indexing is rarely prioritized
Indexing debt is usually not ignored because people do not care.
It is ignored because it sits between roles.
Marketing owns content. SEO owns strategy. Engineering owns infrastructure. No one fully owns “ongoing index hygiene.” So it falls into the category of:
- important, but not urgent
- valuable, but hard to measure immediately
- painful, because the fixes feel manual
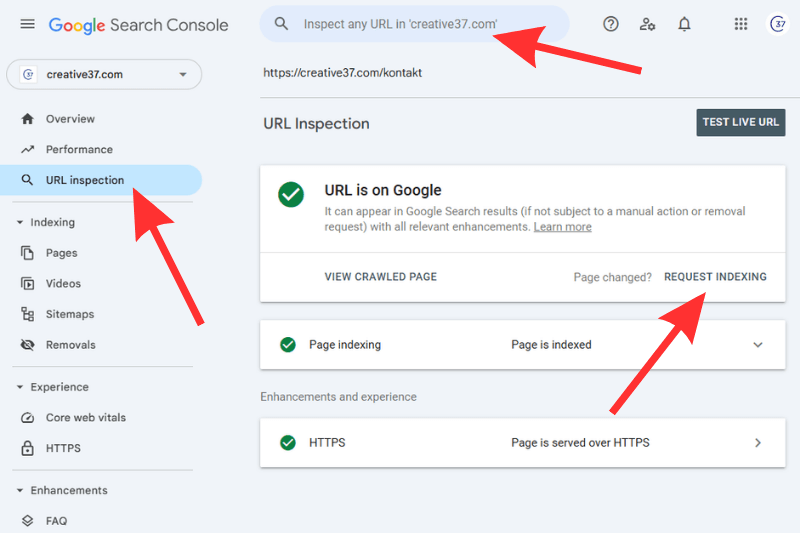
Submitting URLs one by one in Search Console does not scale.
Auditing index coverage once per quarter is a snapshot, not a system.
And even when you find issues, the backlog competes with everything else.
So most sites do what feels productive: publish more content, ship more pages, run more campaigns.
Which increases the size of the indexing problem.
The compounding cost of stale indexing
Indexing debt gets expensive because it compounds in multiple directions at once.
1) Crawl attention gets diluted
If your site has lots of low-value, outdated, or poorly linked URLs, search engines can spend time crawling things that do not matter, which reduces how often they revisit the pages that do matter. Crawl budget is not a myth for large sites, it is explicitly something Google talks about optimizing for “very large and frequently updated” sites.

2) Rankings decay without a clear cause
When important pages are not revisited often, competitors can outrank you simply by staying fresher, more connected, and more crawl-friendly. You might blame “the algorithm” when the real issue is that the page has stopped getting enough attention.
3) Conversions drop because search traffic lands on stale reality
This is the underrated one. Indexing debt is not just SEO.
If Google is surfacing an older understanding of your pages, users can land on:
- outdated feature claims
- old screenshots
- old positioning
- deprecated offers
- pages that are missing key internal paths to conversion
That creates friction, distrust, and lost revenue. You are paying for the content, hosting, and maintenance, but you are not getting the value because the page is not “alive” in search anymore.
Automating indexing hygiene
Manual fixes can reduce indexing debt, but they do not prevent it from returning.
What you want is indexing hygiene that runs continuously, like uptime monitoring or analytics.
In practice, automated indexing hygiene usually means:
- Detecting index drift: which important URLs exist but are not indexed, or have fallen out
- Finding orphan pages at scale: URLs with no internal links, or only buried links
- Spotting stale pages: key URLs not crawled recently, or not reflecting recent updates
- Prioritizing re-indexing: based on business impact (revenue pages first, not random blog posts)
- Closing the loop: verifying that changes were actually reprocessed
Google’s guidance around crawl budget and crawlable links makes the direction clear: keep the site structure crawlable, keep sitemaps accurate, and help Google discover and prioritize what matters.
The missing piece for most teams is turning that into a repeatable system that does not rely on someone remembering to check.
Clear your indexing debt automatically
Indexing debt is not a failure. It is what naturally happens when a site grows.
The advantage comes from treating it like a system, not a cleanup project.
Clear your indexing debt automatically with Cromojo.



