

Have you ever devoted hours to creating top-notch content only to find that Google is wasting time indexing the wrong pages? It could be your old tag archives, faceted search pages, or random filter URLs in place of your well-written blog posts and product pages. The result? Your best work is obscured as junk pages take center stage.
That’s the reality of index bloat and if you’ve ever felt like Google just isn’t giving the right pages the attention they deserve, you’ve already felt its impact.
What Index Bloat Means

Index bloat happens when Google indexes too many low-value or unimportant pages from your site. These pages don’t add real value to users, but they still take up space in Google’s database.
Imagine it as a library designed to house the greatest books in the world. Rather, the shelves are filled with rough drafts, sticky notes, and receipts. Readers find it more difficult to locate the important books because of the clutter. It hinders your key pages' ability to compete and rank in search engine results.
Example: An ecommerce site with 5,000 products once discovered Google had indexed nearly 30,000 URLs. Why? Every filter combination (color=red, size=medium, price=$20–$40) generated a new URL, and all of them got indexed. None of those filter pages were valuable on their own, but they bloated the index to six times the size of the actual site.
Why Index Bloat is Bad for SEO
On the surface, you might think: “More pages indexed = better.” But it doesn’t work that way. Index bloat actively hurts your SEO.Here’s why:
- Diluted authority: When Google spreads crawl attention across thousands of unimportant URLs, your most valuable pages get less focus.
- Slower crawling: Google has a crawl budget for every site. If it wastes time on thin or duplicate pages, it might miss updates to the ones that matter.
- Lower rankings: A site full of low-quality indexed pages signals to Google that your content isn’t trustworthy or well-managed.
Example: A blogger once realized that every “print version” of her posts was being indexed. Suddenly, she had duplicate versions of every article. Google couldn’t decide which one to show in results, and her rankings plummeted until she cleaned it up.
Identifying Unimportant Pages in the Index
Identifying index bloat is the first step towards resolving it. And you can’t fix what you don’t measure.
You can check by running a site:yourdomain.com search in Google to see roughly how many pages are indexed. If the number is far higher than the actual number of pages on your site, you may have index bloat.
Google Search Console is more precise. The Coverage report will show you which pages are indexed. From there, you can scan for obvious junk like:
- Filtered product URLs (e.g.,
?color=red&size=medium) - Tag archives from WordPress or other CMSs
- Old, thin blog posts with no value
- Internal search results pages (
/search?q=) - Staging or duplicate URLs accidentally left open
Example: A travel site noticed that its internal search feature (/search?q=Paris+hotels) generated thousands of indexed URLs. Those pages weren’t useful for users, but they were clogging Google’s view of the site.
How to Use Noindex and Robots.txt
Once you’ve identified bloat, the next step is pruning. You don’t always need to delete the pages, you just need to tell Google not to index them.
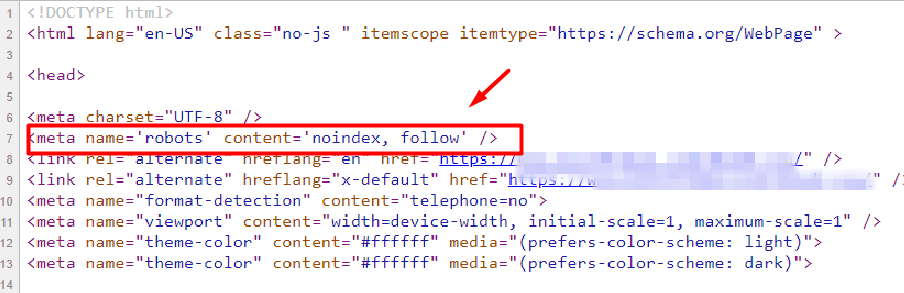
- Noindex tag: Your "keep off the shelf" sign is this. A <meta name="robots" content="noindex"> tag instructs Google not to index that page.Perfect for tag archives, duplicate versions, or thin pages you still want live for users.
- Robots.txt: This is more of a gatekeeper. It blocks crawlers from even accessing certain pages or folders. Useful for things like staging environments, filter parameters, or backend files.
Example: A recipe blog once had every ingredient filter indexed (e.g., “chicken+gluten-free+under-30-minutes”). Thousands of pointless pages piled up. By adding noindex to filter URLs and blocking them in robots.txt, the site’s indexed count dropped back to normal and organic traffic went up.
Monitoring for Accidental Re-Indexing

Here’s the catch: even after you fix index bloat, pages can creep back in. Maybe you updated your theme, removed a noindex tag by mistake, or launched a new site feature that started generating thousands of new URLs.For this reason, constant observation is essential. Making sure the clutter doesn't return is more important than simply cleaning up once.Example: In 2023, an e-commerce website proudly cut down on the number of indexed pages by 80%. However, a year later, auto-generated filter pages were enabled again by a CMS update. Index bloat and ranking declines returned within months.
How Cromojo Helps
Here's where Cromojo really shines. Rather than manually verifying if a page is included in the index or not, you can:
- Track indexed URLs at scale: Find out which pages are included in Google's index and which are not.
- Set alerts for re-indexing:Create re-indexing alerts so you can be informed right away if a page you blocked makes a surprise return to the index.
- Spot trends over time: Historical reports help you see whether index bloat is creeping back in slowly, before it becomes a disaster.
Think of it as your safety net. Once you’ve done the hard work of pruning, Cromojo keeps watch, making sure the weeds don’t grow back and choke out your valuable pages.
Practical Checklist: Fixing Index Bloat
Here’s a quick-reference guide you (or your readers) can use whenever index bloat sneaks up:
Step 1: Identify Index Bloat
- Run a
site:yourdomain.comsearch in Google and compare the number of results to your actual page count. - Open Google Search Console → Coverage Report → “Indexed” pages.
- Look for patterns of junk URLs: filter parameters, tag archives, internal search results, thin content.
Step 2: Prioritize What to Remove
- Mark pages that have little or no user value.
- Check for duplicate versions of important content.
- Don’t remove pages that already rank or bring traffic—focus on the “dead weight.”
Step 3: Apply Fixes
- Add a noindex tag to thin or duplicate pages.
- Block unimportant URLs (like filters or search pages) in robots.txt.
- Remove outdated or unnecessary content completely if it serves no purpose.
- Update and resubmit your sitemap so Google knows the preferred structure.
Step 4: Monitor for Regression
- Recheck Search Console regularly for excluded or reindexed pages.
- Watch for CMS updates or plugins that may generate new junk URLs.
- Use tools like Cromojo to catch accidental re-indexing automatically.
Final Thoughts
Index bloat isn’t just a technical quirk, it’s a silent SEO killer. It clutters your site in Google’s eyes, dilutes your authority, and leaves your best content struggling to shine.The good news? It can be fixed. You can optimize your index and ensure that Google is concentrating on the pages that are really important by identifying the junk pages, applying noindex or robots.txt, and setting up monitoring to stop regressions.Because, in the end, SEO is about ensuring that your best work receives the attention it merits, not about packing Google's shelves with every scrap of content.

.png)

